
What is Translation Memory
At its core, Translation Memory is a feature that captures and stores previously translated content for future use. In Translator++, this means that translations are not confined to individual projects. Instead, the Translation Memory captures translations across projects, creating a repository of language solutions that can be harnessed whenever needed.
Terms to Know
Before we dive into the details of how to use Translation Memory in Translator++, let’s become familiar with some important terms associated with this feature:
- Recall: The act of retrieving a previously recorded translation from the database.
- Memorize: Storing a translation into the database for future reference.
- Re-Memorize: Overwriting an existing translation in the database with a new one.
- Forget: Removing a translation from the database.
- Organic Translation: Translations manually input by human translators.
How to Use Translation Memory in Translator++
Basic Functionality
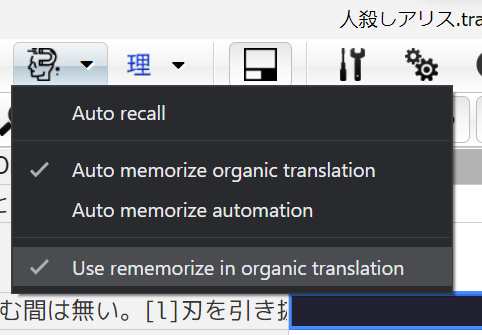
By default, Translation Memory in Translator++ automatically records organic translations—translations manually input by human translators. This allows users to effortlessly build up their translation database as they work. It’s worth noting that while you can enable auto-recording for automated translations (Automation and MTL), it’s generally not recommended due to potential inconsistencies.
Memorizing and Re-Memorizing
When a translation is entered manually, it’s stored in the Translation Memory database. By default, existing translations in the memory will not be overwritten by new ones. However, if you wish to update an existing translation with a new one, you can use the “Re-Memorize” function. This action replaces the previous translation with the new one, ensuring that the memory remains up-to-date. This can be done through the context menu or by enabling the “auto re-memorize” option, which automatically updates the memory whenever a translation is manually entered.

Recalling Memorized Translations
Utilizing the memorized translations stored in the Translation Memory is incredibly straightforward in Translator++:
Context Menu
Right-click on a cell within the translation grid to access the context menu, then select Translation Memory -> Recall.
Keyboard Shortcut
Press CTRL+r to recall the translation in the selected cell.
Row Info Pane
The “Memory” tab in the Row Info pane displays memorized translations and alternatives. Clicking a translation here instantly applies it to the selected cell. The light bulb icon, turning yellow, hints at related records for the focused row.
Automatic Recall
When performing machine translation, Translator++ automatically retrieves exact match translations from the memory, promoting quality translation over MTL.
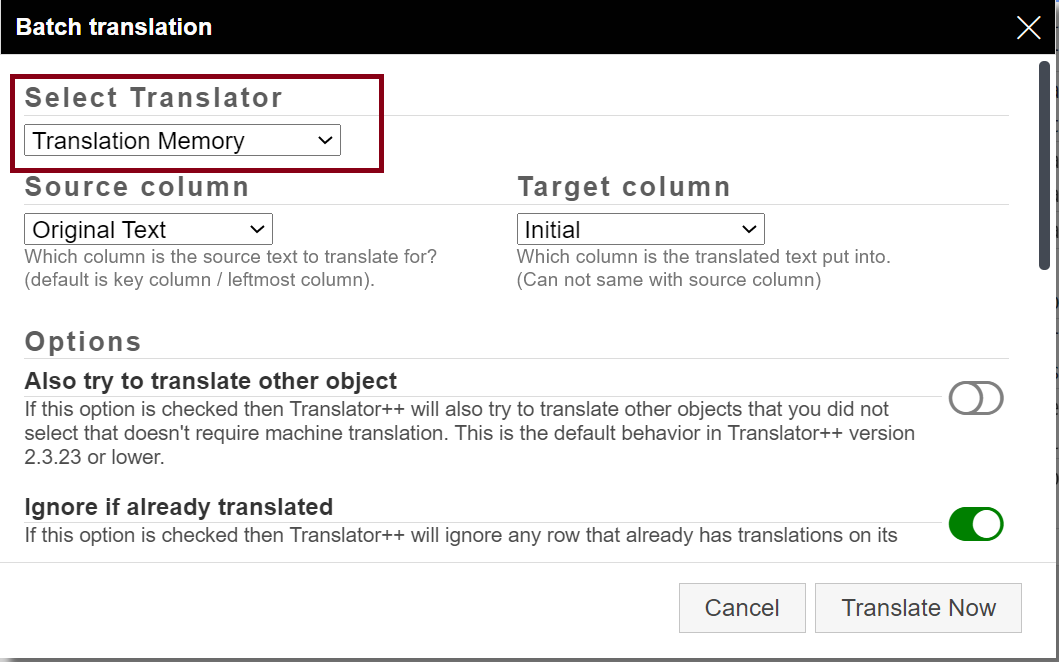
Using TM as a Translator Engine
Translator++ allows you to use Translation Memory as the translation engine:

Supported Databases
Translator++ provides support for two distinct database options, ensuring flexibility and convenience for users with varying needs:

IndexedDB: Lightweight and Local
The IndexedDB serves as a local, lightweight database that requires no setup. It’s readily available out of the box, making it an accessible option for individual users. This solution offers simplicity without the hassle of configuration, allowing translators to jump right into using the Translation Memory feature.
MySQL: Empowering Enterprise-Grade Capability
For those seeking a robust, enterprise-grade database solution, Translator++ offers MySQL integration. With MySQL, you can harness the power of a comprehensive translation repository database that can be utilized by you and your team. This option ensures centralized management and collaboration, allowing multiple team members to contribute to and benefit from a single translation repository.
Click here to learn more on how to setup Maria/MySQL Database for Translator++’s TM