
User Guide: Parsing JSON Files in Translator++
This guide will walk you through using the JSON parser feature in Translator++, which allows you to extract translatable text from .json files.
Getting Started
To begin, start a new project in Translator++. And select JSON as the type of the project.
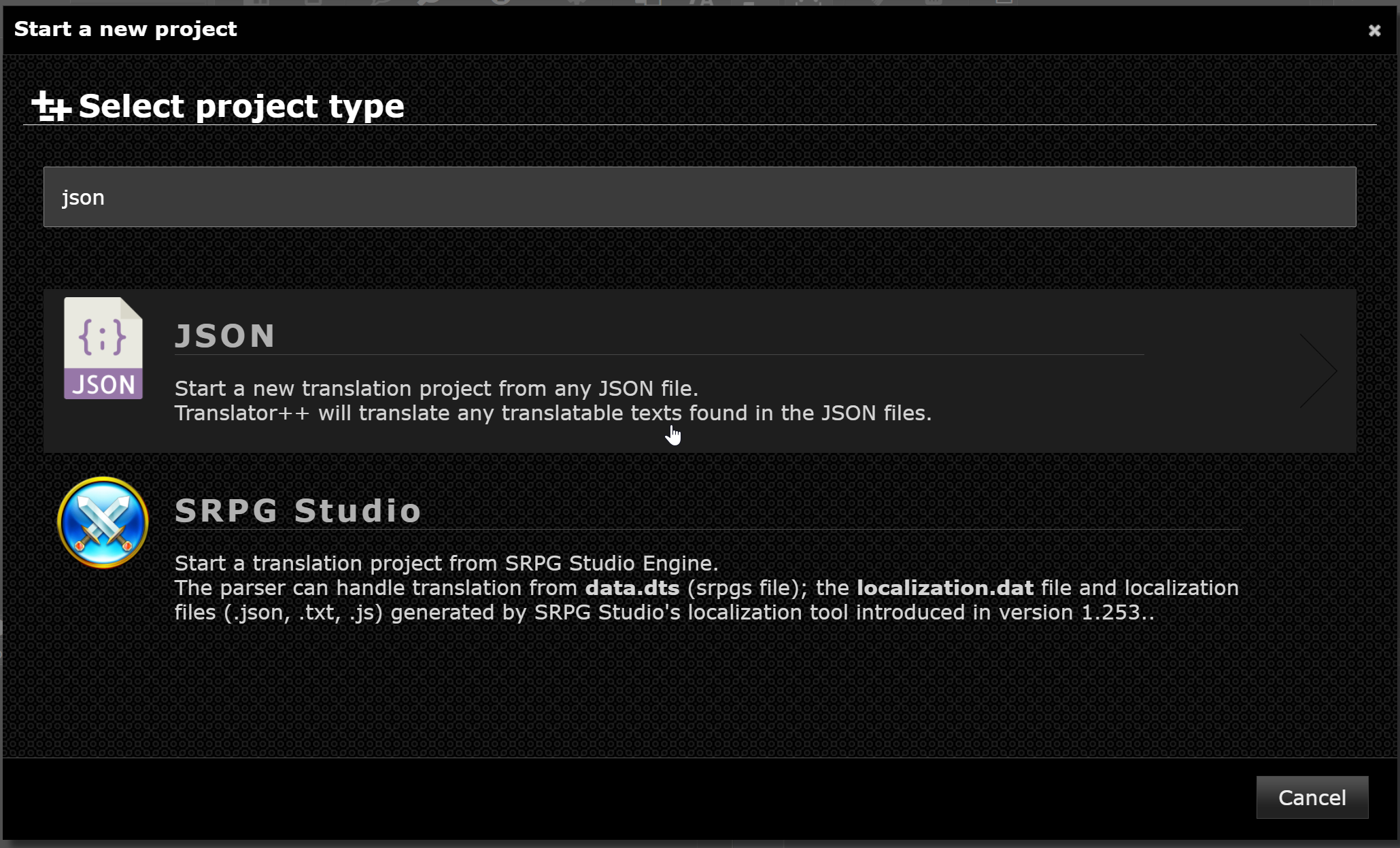
After that you will be prompted to select a folder containing your JSON files. Translator++ will scan this folder and its subfolders for any .json files to process.
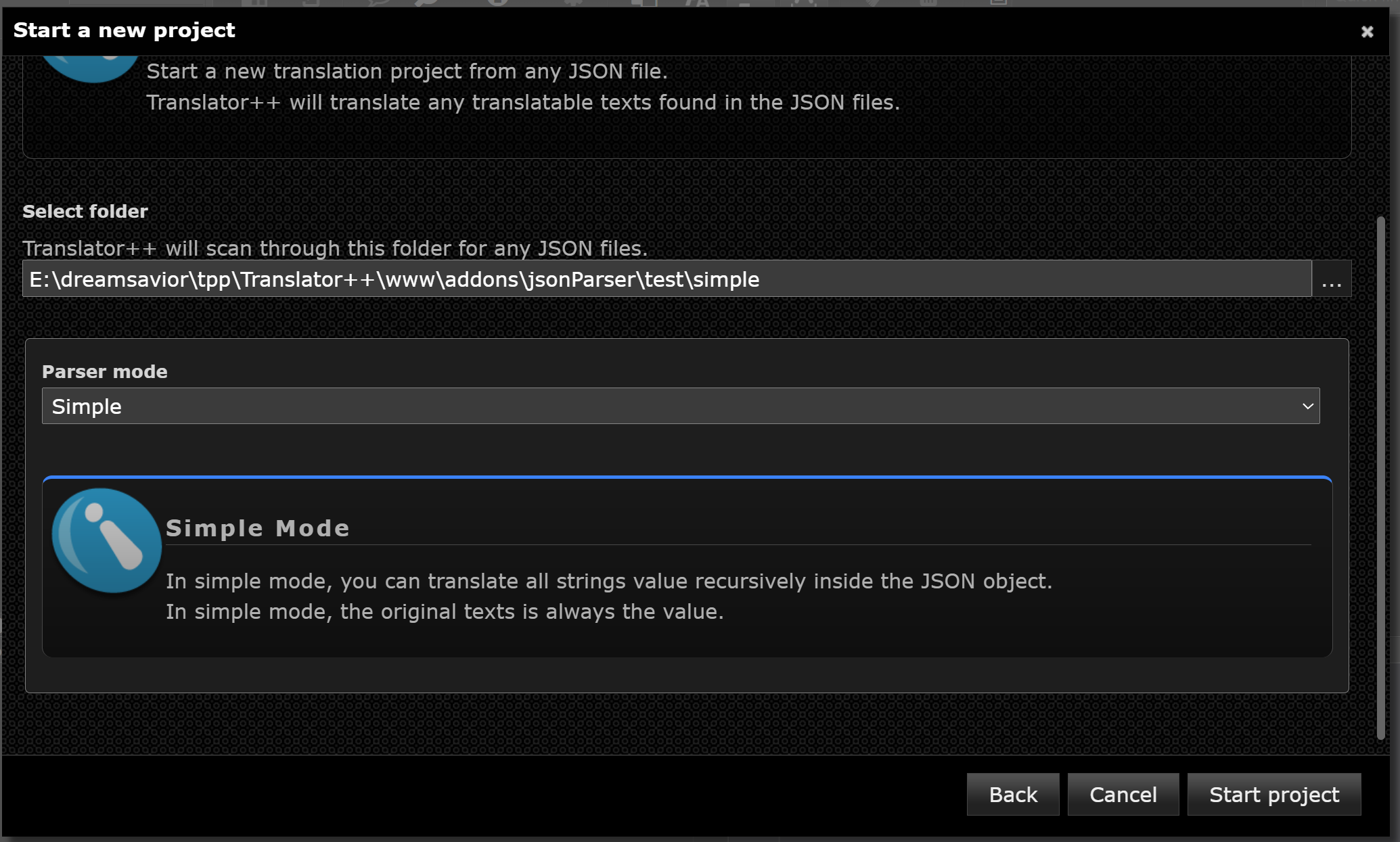
After selecting the folder, you must choose a Parser Mode. There are two modes available: Simple Mode and Advanced Mode.
Simple Mode
Simple Mode is the easiest way to get started. It recursively scans the entire JSON structure and extracts all string values for translation. No additional configuration is needed.
In this mode, the original text for translation is always the value of a key-value pair.
Example
Consider the following JSON structure:
{
"key1": "text to translate",
"key2": "another text to translate",
"key3": {
"key4": "text to translate in nested object",
"key5": [
"text to translate in array",
"another text to translate in array"
]
},
"same text will be merged": "text to translate",
"will not be captured" : {
"because the value is blank": "",
"and this is a number": 12345,
"and this is a boolean": true,
"and this is a null value": null
}
}
Result
The parser will extract all string values, including those in nested objects and arrays. It will ignore non-string values like numbers, booleans, nulls, or empty strings. The result in the translation grid will be:
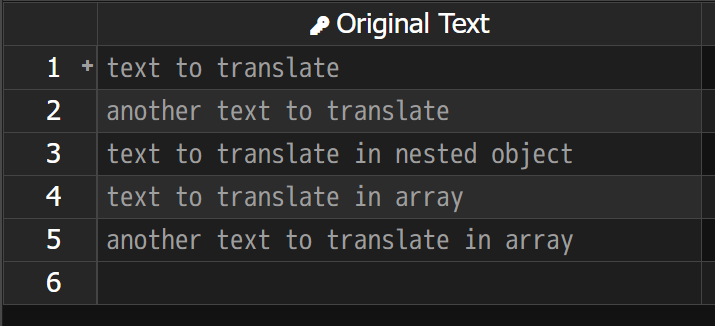
So, you might be wondering how to capture the values in the "will not be captured" fields from the example above. To do that, you’ll need to use Advanced Mode.
Advanced Mode
Advanced Mode provides fine-grained control over which parts of the JSON file are parsed. This is achieved by defining a set of rules. Each rule can target a specific object or array within the JSON structure using a JSONata query.
How It Works
You can add multiple rules to define how different parts of the JSON are parsed.
- For objects: The parser uses the key as the original text and its value as the default translation. The parser will register entries if the value is a string, null, or undefined.
- For arrays: The parser registers all string values within the array as translatable texts.
Configuration Fields
- Label: A custom label for the rule. This will be included as context for the extracted text.
- Query: A JSONata query to select a specific part of the JSON object. If left blank, it targets the root of the object.
Example
Let’s use the same JSON file as before. Simple Mode cannot capture keys whose values are blank or null. With Advanced Mode, we can capture them.
{
"key1": "text to translate",
"key2": "another text to translate",
...
"will not be captured" : {
"because the value is blank": "",
"and this is a number": 12345,
"and this is a boolean": true,
"and this is a null value": null
}
}
We can define two rules to parse both the root-level keys and the keys within the nested “will not be captured” object.
Rule 1:
- Label: Root
- Query: (blank)
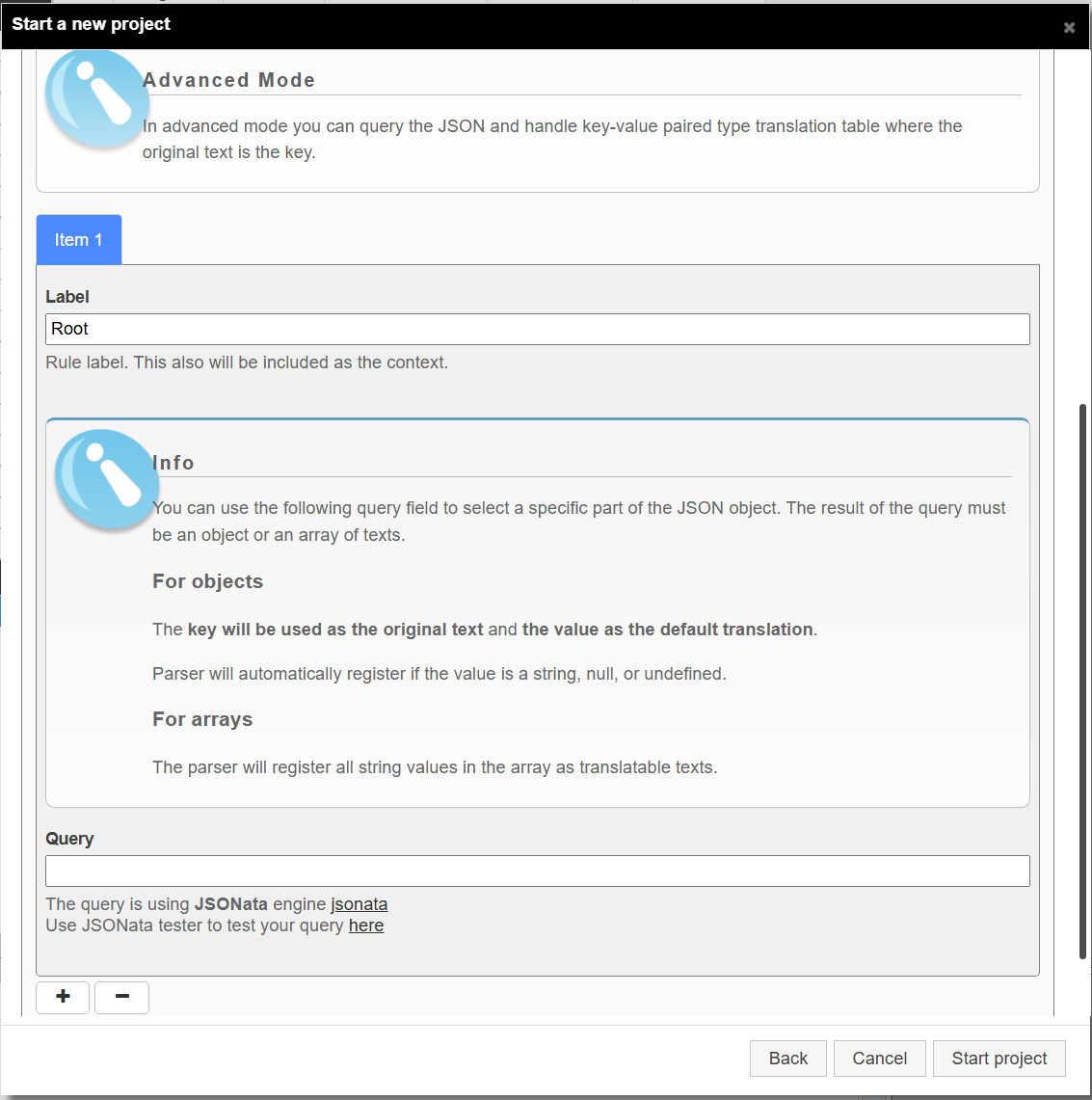
This rule targets the root object. It will extract key1, key2, and same text will be merged as original texts.
Rule 2:
- Label: rule2
- Query:
$.“will not be captured”
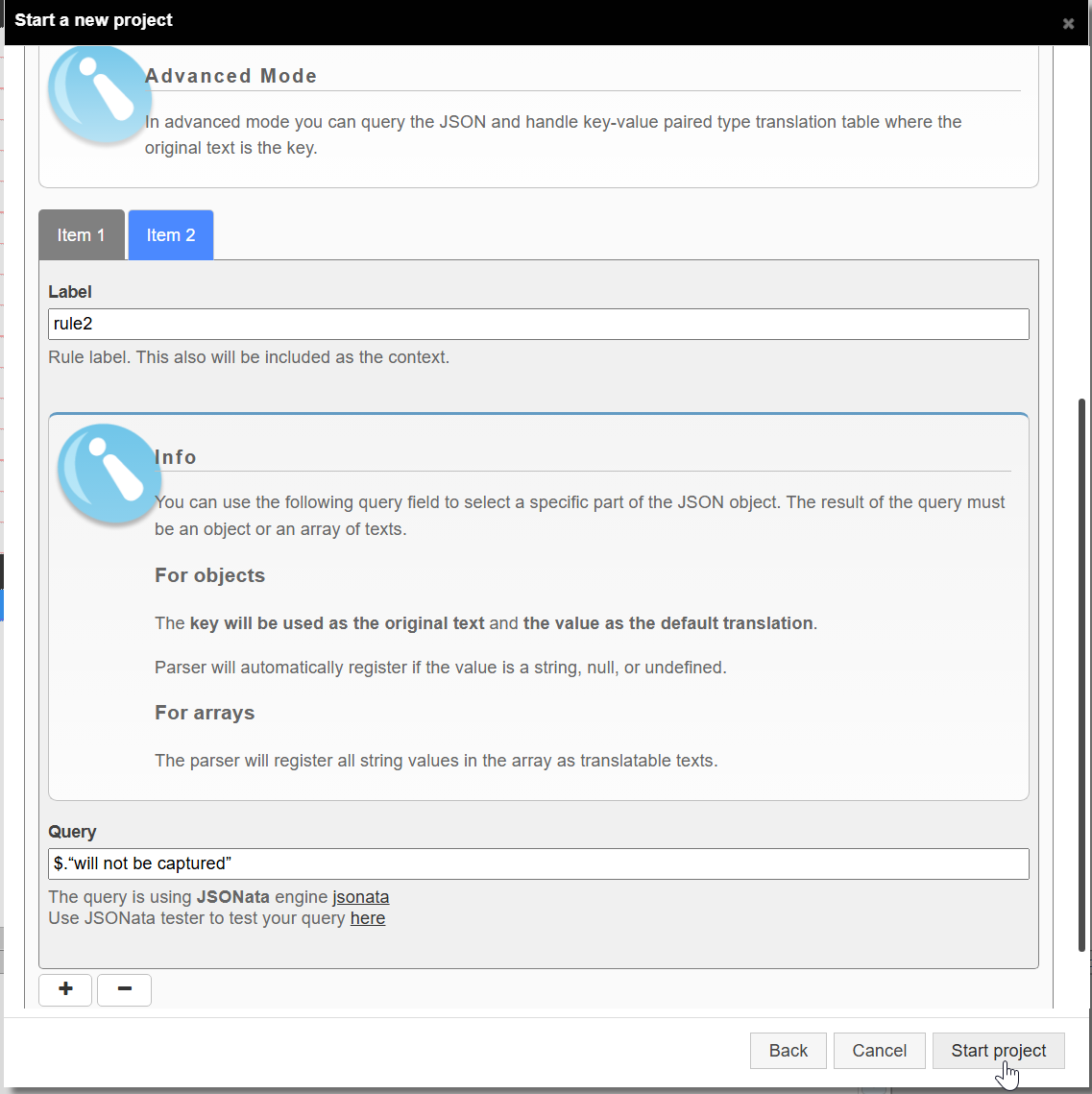
This rule specifically targets the nested object. It will extract because the value is blank and and this is a null value as original texts.
Result
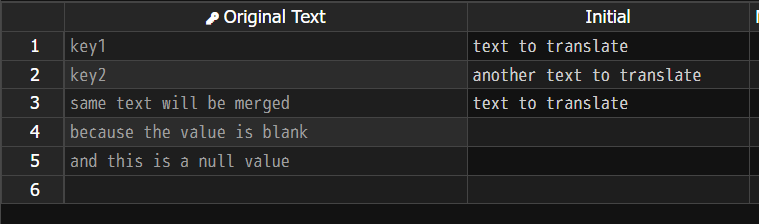
By combining these two rules, the parser will extract keys from both the root and the specified nested object. The translation grid will show the following:
| Original Text | Initial |
|---|---|
| key1 | text to translate |
| key2 | another text to translate |
| same text will be merged | text to translate |
| because the value is blank | |
| and this is a null value |
This allows for a more flexible and powerful way to handle complex or non-standard JSON files.
Handling Arrays
When your JSONata query selects an array of strings, the parser behaves like Simple Mode for that array. It captures the value of each element in the array as the original text. This is the most practical way to handle a list of translatable strings.
Example:
{
"chapters": [
"Chapter 1: The Beginning",
"Chapter 2: The Journey",
"Chapter 3: The End"
]
}
- Query: $.chapters
- Result: The parser will extract “Chapter 1: The Beginning”, “Chapter 2: The Journey”, and “Chapter 3: The End” as translatable texts.
A Note on Direct String Queries (Unsupported)
A query that resolves to a single, direct string value will not work. Translator++ requires a reference (an object or an array) to correctly map the translation back to the right place in the JSON file. A raw string doesn’t provide this structural reference.
{
"app_title": "My Awesome App"
}
- Incorrect Query: $.app_title
- This query resolves to the string “My Awesome App”, which cannot be processed.
- Correct Approach: To translate this, your query must target the parent object.
- Correct Query: $
- Result: The parser will select the root object, identify “app_title” as the key (original text), and use “My Awesome App” as its initial translation.
JSONata Query Basics
JSONata is a lightweight query and transformation language for JSON data. In Translator++, you use it to tell the parser exactly which part of the JSON you want to process. The result of your query must be an object or an array of texts.
Here are some common patterns:
$or leaving the field blank targets the root object.$.some_objectselects a nested object.$."key with spaces"selects a key with special characters.
This allows for a more flexible and powerful way to handle complex or non-standard JSON files.
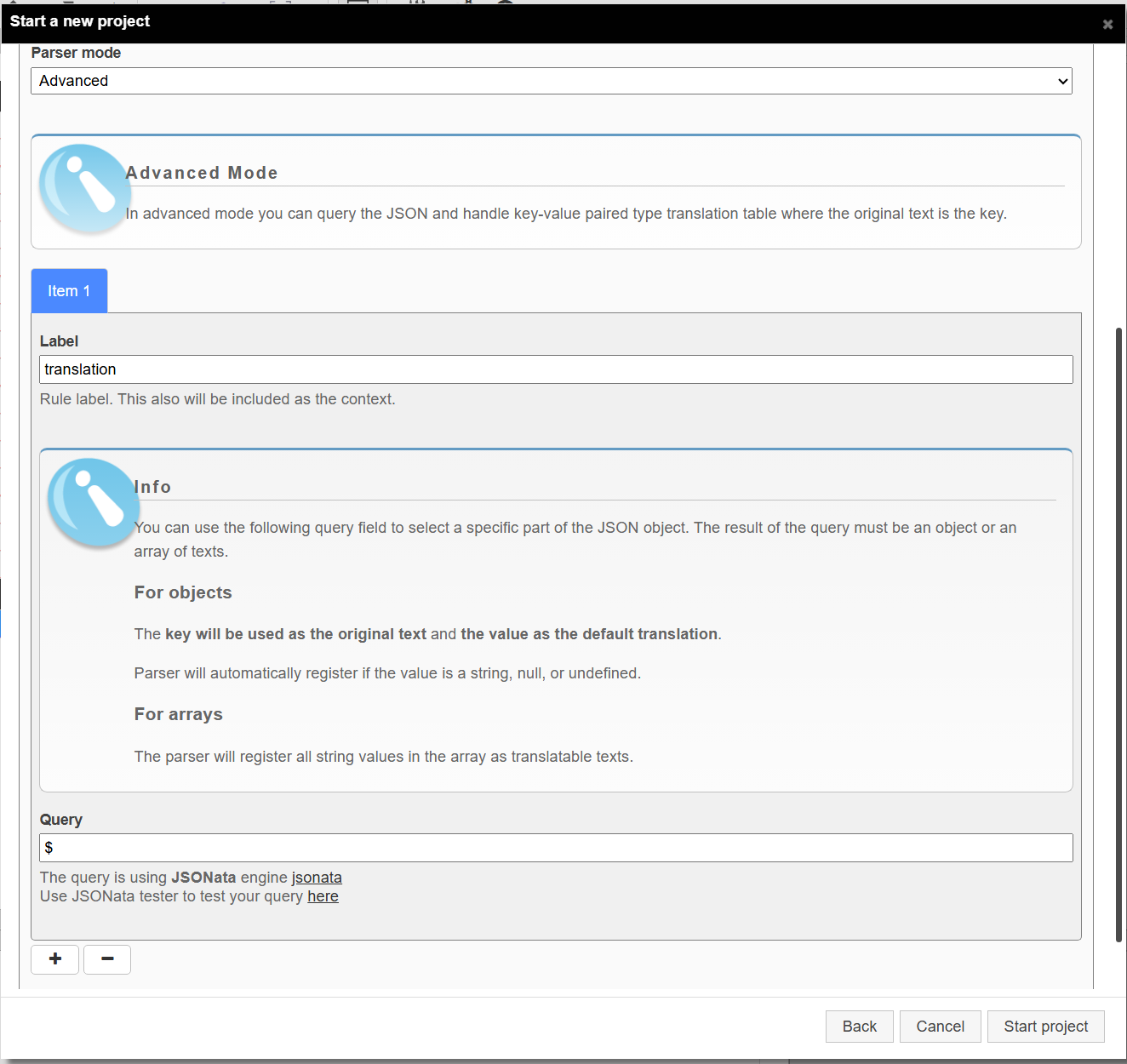
Example 1. Handling JSON with key-value pairs
Example key-value pairs data:
{
"text to be translated": "",
"text to be translated 2": "",
"text to be translated 3": ""
}You can create the project with advanced mode. Then fill the query with $
Useful Links
- Try JSONata: https://try.jsonata.org/
- An interactive online tool to test your JSONata queries against your JSON data before using them in Translator++.
- JSONata Simple Queries Guide: https://docs.jsonata.org/simple
- Official documentation covering the basics of writing JSONata queries.