
Hello fellow translators!
This month, Translator++ comes with several exciting new features and bug fixes to make your translation experience even smoother.
⚙️ Improved “HTML Cloaking Wrapped” for LLM
TL;DR:
Batch translation with HTML Cloaking Wrapped makes translation faster and lighter than using JSON — especially for local LLMs, which tend to generate JSON output more slowly.
Before we dive into why this improvement matters, let’s first understand the background.
Imagine you have 10 lines of text to translate. Which do you think is more efficient — sending them one by one to the translation engine, or sending all 10 lines at once and splitting the results afterward?
It’s already proven that translating in bulk is faster, cheaper, and more efficient. Even better, with LLMs you can often get higher-quality translations when sending text in bulk, since the model can understand the context and nuances of the entire set.
This has always been the core technique behind Translator++’s batch translation system.
🧩 The Challenge
When multiple lines are sent together as plain text, the translator engine must know how to correctly distribute each translated segment back to its original line. That’s the tricky part — and it becomes even more challenging with LLMs, whose outputs can sometimes be unpredictable.
To solve this, Translator++ uses several algorithms, including JSON Cloaking. This method wraps the text in a JSON array so that the LLM can return translations in a structured format that’s easy to parse back.
💡 JSON Is Great — But Resource-Heavy
If you’re using powerful cloud-based LLMs like OpenAI or Gemini, you may not notice any slowdown.
However, local LLMs often struggle with JSON output — it’s computationally expensive and tends to take longer. We recently discovered that many models internally retry multiple times to ensure their JSON output is valid, which adds latency.
That’s where HTML Cloaking Wrapped comes in.
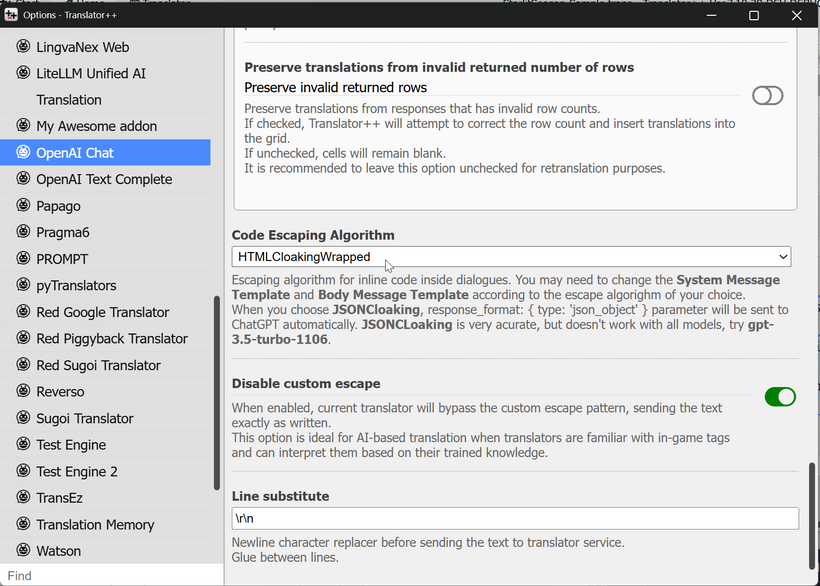
Instead of JSON, this method isolates each line within HTML tags. Since HTML is a universally understood format for most LLMs, this approach is less demanding and faster to generate.
You can now use this new “escape” algorithm to speed up your batch translations — and yes, a ready-to-use preset for HTML Cloaking Wrapped is already included!
🔍 Smarter Search
Many users have asked for an easier way to find untranslated lines — and it’s finally here!
You can now search for untranslated rows directly in the Find feature.
Simply choose “Untranslated” as the target.
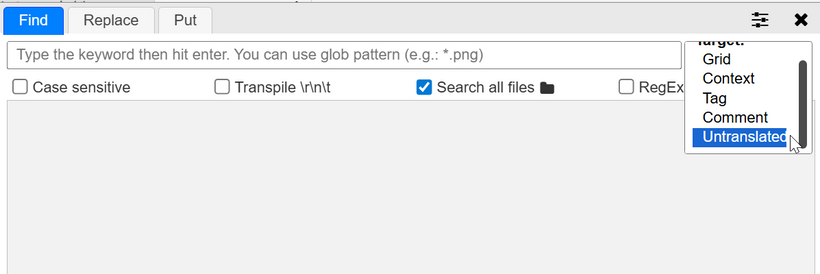
To list all untranslated lines, just use the asterisk (*) wildcard.
All these updates and bug fixes are available in Translator++ version 7.10.29, available for all patrons.
Happy translating!
Dreamsavior